WIP【備忘録】DBの論文を読む : 誰もが知っておくべきテクニック
そろそろデータベースに関するちゃんとした基礎知識をつけたいという思いがあるので、Readings in Database Systems, 5th Edition を読んでいこうと思う。
URL: http://www.redbook.io/index.html
この本は、DB に関する古典的な論文から、近年の特に重要な論文まで、章ごとに短い解説とともに紹介されている。
今回は Ch3 誰もが知っておくべきテクニック を読む。
紹介された論文
Access path selection in a relational database management system. (1979).
- SQL文から実行計画を作成する際に使用されるコストの計算について記載している
Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging. (1992).
Granularity of Locks and Degrees of Consistency in a Shared Data Base. (1975)
- ロックとトランザクションの分離レベルに関する論文
Concurrency Control Performance Modeling: Alternatives and Implications. (1987)
- aaa
Transaction Management in the R* Distributed Database Management System. (1986)
- aaa
解説を読んだ
この章では、DB設計における特に重要な概念として、以下の項目に関する論文が紹介されている。
- 実行計画 (クエリの最適化)
- データベースのリカバリ
- 同時実行制御
- 分散システム
論文1について
Abstract
SQL のような高レベルのクエリやデータ操作言語では、リクエストはアクセスパスを参照せずに非プロシージャルに記述されます。本論文では、述語のブール式として目的のデータをユーザが指定した場合に、System R が単純な(単一の関係)クエリと複雑な(結合などの)クエリの両方に対して、どのようにアクセスパスを選択するかについて説明する。System R は、データのリレーショナルモデルに関する研究を行うために開発された実験的なデータベース管理システムです。System R は、IBM San Jose Research Laboratory のメンバーによって設計・構築されました。
出典: Access path selection in a relational database management system(筆者訳)
感想とメモ
この論文ではオプティマイザがどのように実行計画を建てるのか、また実行コストの計算方法を解説していた。
正直読み終わったあとも50%ぐらいの理解しかできていない気がする...。
また今度時間のあるときに挑戦したい。
さて、論文の内容に入る前に、そもそもオプティマイザが何故必要であるかを復習する。
SQL は宣言的な言語なので、ユーザーはタプル(レコード)の物理的配置を知らなくていいし、タプルへの効率的なアクセス方法を指定する必要がない。
では誰がそれを指定するかというとオプティマイザがその役割を担う。
すると、オプティマイザはどうやって最適なアクセス方法を選び出すのかという課題が発生するが、この論文ではその話をする。
まずはオプティマイザがどのタイミング動くかを考えよう。
クエリが入力されたら、まずはパーサーにより文法上(syntax)のチェックが行われた後、SELECT list,FROM listやWHERE tree等のクエリブロックに分解される。
そして、クエリで必要なテーブルやカラムをカタログ上に存在するかを確認し、以下のことを行う。
- カタログから統計量や利用可能なアクセスパスの取得を行う
- クエリブロックの評価順を決定する
- コストを最小にするアクセスパスを選択する
- アクセスパスは
structual modification of the parse treeで表現される
- アクセスパスは
どうやらオプティマイザはこの段階で機能するらしい。
ここら辺の話は Ch1 でもやったのである程度は想像できる気がするな。
ここでの結果は実行計画と呼ばれ、ASL(Access Specification Language)で記述される。
ただ、GROUP BYとかORDERBYはどのクエリブロックに属すんだろう?
一応、Postgres公式から実行計画の説明を引用する。
実行計画は、問い合わせ文が参照するテーブル(複数の場合もある)をスキャンする方法(単純なシーケンススキャン、インデックススキャンなど)、複数のテーブルを参照する場合に、各テーブルから取り出した行を結合するために使用する結合アルゴリズムを示すもの
上のタイミングからもわかるように、オプティマイザはカタログから取得した統計量をメインに使用し最適なアクセスパスを選択する。
ところで、実行計画はどのように表現されるのか。
例としてPostgresの公式にある例を引用する。
例
integer列を1つ持ち、10000行が存在するテーブルに対して、単純な問い合わせを行った場合の問い合わせ計画を表示します。
EXPLAIN SELECT * FROM foo;
QUERY PLAN
---------------------------------------------------------
Seq Scan on foo (cost=0.00..155.00 rows=10000 width=4)
(1 row)
引用元: [PostgreSQL 9.2.4文書 EXPLAIN](https://www.postgresql.jp/document/9.2/html/sql-explain.html)
ここで気になるのが、Seq Scanとcost=...だと思う。
それ以外の意味はなんとなくわかりそうだ。
まずは、このScanの説明をする。
ScanはRSSからどのようにタプルを取得するかを表している。
少しだけRSSの復習をしよう。
RSSは物理的なストレージに関してアクセスパスやロックなどの管理を行う。
テーブルはタプルの連続したコレクション(ページ)として保存され、更にページの論理的な単位をセグメントと呼ぶ。
1つのページに複数のリレーションが含まれることはあるが、1つのリレーションが複数のページにまたがることはない。
復習終わり。
では、RSSへのアクセスはどのように行うのか。
メジャーな方法を2つ挙げる。
- セグメント Scan (Full(Seq) Scan)
- セグメントのすべてのタプルを調査する
- 特徴: 全てのページを1回ずつ調べる
- インデックス Scan
- キーとタプルIDをマップする何らかの別のデータ構造を用いて、インデックスを調査しキーとマッチしたタプルのみを取得する
- 特徴: 必要なページのみを調べるが、同じページ内の2つのタプルがインデックス上で離れている場合、同じページに2回アクセスする
- 補足: タプルがインデックス順でセグメントのページに挿入されている、或いはインデックスに対する物理的な近接関係が保たれているとき、インデックスがクラスター化されている、という。
先の実行計画の例にあったSeq Scanは、「テーブルをセグメントスキャンする」という意味だとわかる。
因みに、この2つのScanは追加でSARGS(search arguments)と呼ばれる述語(predicates)を取る事ができる。
SARGを指定した場合、Scanの際にタプルがそのSARGを満たしている場合のみそれをRSI callerに返す。
このため、RSI callのオーバーヘッドを抑えることができる。
ただ、任意の述語がSARGとして指定できるわけではないらしい。
話を戻そう。
次に気になるのがcost=..だが、これはそのクエリの推定コストを示している。
実行計画は(推定)最小コストのアクセスパスであるが、2つの疑問がある。
Q1. コストの計算ってどうやるの?
Q2. 最小コストのアクセスパスの探索方法は?
Q1から取り組もう。
論文によれば、オプティマイザは以下の計算式でアクセスパスのコストを計算する。
Cost = (I/O cost) + W * (CPU cost)
≒ (Page Fetches) + W * (RSI Calls)
W: I/OとCPUコストの相対重み
この計算式はI/Oコストの近似としてページフェッチを、CPUコストの近似としてRSI Callを用いている。
重みWは事前に決めるっぽいんだけど、どうやって決めるんだろうとは思う。
まずは1テーブルのみが関わるようなクエリのコストを計算する場合を考えよう。
この場合、WHERE treeとFROM listのコストが計算できればよい。
このコスト計算にはカタログから得られる統計量を用いる。
「あれ?SELECT listは?」と思ったそこの君。わたしもそう思った。
ただ、行志向DBならどの列を持ってきてもコストが変なさそうな気もする。
最初はWHERE treeのコストを計算する。
計算のため、以下のような統計量を定義する。
リレーションをTとする。 - NCARD(T) ... Tの濃度 - TCARD(T) ... Tのタプルをもつセグメントのページ総数 - P(T) ... TCARD(T) / (セグメント内の非空のページ数)。 セグメント内でTのタプルを持つページの割合を表す TのインデックスをIとする。 - ICARD(I) ... Iが持つキーのユニーク数 - NINDX(I) ... Iのページ数
これらの統計量から、オプティマイザは述語リストの論理因子夫々に対し選択係数Fを算出する。
WHERE treeのコストはこれらを用いて計算する。
論文には計算例がいくつか載っている。
うーん、この結果例のいくつかは上手く咀嚼できない。今度見直そう。
fig1
次いで、FROM listに関するコスト計算を考える。
QCARD (query cardianlity) ... (FROM listに含まれるTのNCARDの積) * (WHERE treeに含まれる論理因子のFの積) RSICARD (number of expected RSI calls) ... (FROM listに含まれるTのNCARDの積) * (SARGの選択因子)
SARGはRSIを通すタプルをフィルタリングすることを思い出そう。
これでWHERE treeとFROM listに関するコストが計算できるので、アクセスパスのコストが計算できる。
論文に記載されているコスト例を引用する。
(predsは述語を表す)
fig2
これでQ1が片付いた。
次にQ2に取り組もう。
さて、1リレーションの最小コストアクセスパスは利用可能なアクセスパスのコストを評価することで得られるが、クエリにGROUP BYやORDER BYが含まれる場合、最小コストのパスを以下の2つに関して調査する必要がある。
interesting orderでタプルを取得するアクセスパスunorderdでタプルを取得するアクセスパス
ここで、interesting orderはGROUP BYやORDER BYで指定された順序を指し、unorderdはそれ以外の順序を指す。
何故2つのパスを調べる必要があるのか。
GROUP BYやORDER BYがある場合、aのコストと比較するべきは(bのコスト + QCARDのタプルをソートするコスト)となるからだからだ。
そのため、コストはタプルの並び順と共に計算されることになる。
例えば、インデックスAの昇順でScanする場合、(コストC, A ascend)の組が計算される。
このように夫々のアクセスパスのコストを計算し、最小コストのパスを探すことで実行計画を作成する事ができる。
ここまでの感想としては、個々の説明は何となくわかるものの、全体の関係や実例があまり理解できなかった。。。
ただ、コストがどんな風に計算できるかのざっくりとしたイメージはつけることができたので、そこは良かったと思う。
せっかくなので、論文内でも紹介されているJoinのコストについてもメモしておく。
まずは以下のように言葉を定義する。
外表 (outer relation) ... joinする2つのテーブル(relation)の内、最初にタプルが取得されるテーブル。
内表 (inner relation) ... joinする2つのテーブル(relation)の内、次にタプルが取得されるテーブル。
これはouter relationから取得したタプルによって異なる。
まずはJoinアルゴリズムの復習をしよう。
この論文で紹介されているアルゴリズムはNested Loop JoinとMerge Joinだけだが、Hash Joinも広く使用されていると思うのでこれもついでにまとめておく。
ただ、アルゴリズムの解説自体は外部サイトでわかりやすい説明があったのでそれを引用するに留める。
ネステッド・ループ結合(Nested Loop Join)
nested loop joinは以下のようなアルゴリズムだ。
NESTED LOOPS JOINとは,一方の表から1行ずつ行を取り出し,もう一方の表のそれぞれの行に突き合わせて,結合条件を満たす行を取り出す入れ子型のループ処理の結合方法です。
アルゴリズムのイメージや性質は以下のサイトがわかりやすい。
https://bertwagner.com/posts/visualizing-nested-loops-joins-and-understanding-their-implications/
マージ結合(Marge Join)
marge joinは以下のようなアルゴリズムだ。
MERGE JOINは,結合列でソートして,結合列の値が小さいものから順に突き合わせるため,効率が悪いです。MERGE JOINの中でも,SORT MERGE JOINは,結合するそれぞれの表から行を取り出す際に,作業表を作成しソートするため,特に処理効率が悪いです。
アルゴリズムのイメージや性質は以下のサイトがわかりやすい。
https://bertwagner.com/posts/visualizing-merge-join-internals-and-understanding-their-implications/
ハッシュ結合(Hash Join)
hash joinは以下のようなアルゴリズムだ。
外表の結合列を基に作成したハッシュテーブルと,内表の結合列をハッシングした結果を突き合わせて表を結合します。 この結合方式をハッシュジョインといいます。
出典: Hitachi Advanced Data Binder AP開発ガイド
解説はおなじみのここがわかりやすい。
https://bertwagner.com/posts/hash-match-join-internals/
次にコストの話をしたいのだが、先にN組のjoinについて幾つか性質を話す必要がある。
N組のJoinについて
N組のjoinは2組のjoinを繰り返すことで行われる。
繰り返しの順序はN!パターン存在し、N-joinの結果の濃度は変わらないが、N-joinのコストはパターンによって大きく異なる。
例えばA, B, Cのテーブルがあった場合、この3つのJoinは、以下のようなパターンが考えられる。
- AとBのjoinを行い、その結果とCをjoinする
- BとCのjoinを行い、その結果とAをjoinする
- AとCのjoinを行い、その結果とBをjoinする
ここで注意したいのが、最初のjoinは次のjoinより先に完了している必要はないということだ。
例えばAとBのjoinで結合されたタプルを取得して直ぐにCとjoinすることで3-joinの結合タプルを得られる。
また、Nが大きくなると組み合わせは爆発的に増えるが、いくつかの工夫によって高速化できる。
- k+1回目のjoinのコストは最初のk個のjoinの方法にはよらないため、部分集合のコストを計算することを繰り返す
- 論理的に不可能なjoinの順番がある場合、それを弾く
- 例えばT1とT2は列Aで結合し、T2とT3は列Bで結合するとき、(T1とT3のjoin) -> (T2とのjoin)は不可能
これでようやくjoinのコストについて説明できる。
例の如く、いくつか言葉を定義する。
C-outer(path) ... pathによって外表をスキャンするコスト C-inner(path) ... 全ての述語を適用し内表をスキャンするコスト N ... (適用可能?)述語を満たす外表のタプルの濃度
MEMO:
ここでいくつか疑問がある。
1. C-innerのpathの意味とコストへの影響関係
2. applicable predicates(適用可能述語)とは?joinに使用している述語で良い?
Nは以下のように計算できるらしい。
N = (これまでjoinしてきた全表の濃度の積) * (全ての(適用可能)述語の選択因子の積)
これらのコスト値からjoinアルゴリズムのコストが計算できる。
C-nested-loop-join(path1, path2) = C-outer(path1) + N * C-inner(path2) C-merge-join(path1, path2) = C-outer(path1) + N * C-inner(path2)
上の式からわかるように、2つのjoinアルゴリズムのコスト式は同じだ。
しかし、実用上ではmerge-joinの方が高速である場合があるが、それは時折merge-joinはinner Scanのコストが非常に低くなることがその理由の一つだと記載があった。
ただ、Joinのコストに関する話はもう少し詳しくしてほしかった感がある。
私がきちんと理解するにはもう少しわかりやすい資料を探す必要がありそう。
論文には実際にJoinを含むクエリの探索例やネストされたクエリのコストについて記載がされているので、そちらも参照してほしい。
とはいえ、「じゃあ、結局この3つのJoinアルゴリズムはどう使い分ければいいん?」という問の答えは知りたかったので、下記表にまとめた。
(下表はSQL実践入門(ミック)を参考にした)
| Pros | Cons | |
|---|---|---|
| inner loop | - 駆動表が小さく、内部表のindexが使用できる場合高速 - メモリとディスクの消費が少ない(OLTPに適す) - 非等値結合でも使える |
- 双方の表が大きい場合は不向き - CPUに負荷がかかる傾向 - 内部表のindexが使えない場合は不向きか |
| (sort) merge | - 表がソートされている場合高速 - 大規模な表同士の結合に適する - 非等値結合でも使える |
- 表がソートされていない場合低速 - 入力に多数の重複が含まれている場合、低速になる恐れ(tmpdbが使用される) - メモリ消費が激しく、メモリ不足になると性能が大きく下がる |
| hash | - 非等値結合では使えない - 大規模な表同士の結合に適する |
- メモリ消費が激しく、メモリ不足になると性能が大きく下がる - hashテーブルの構築はブロッキング操作(?) - |
実行計画について更に興味がある人やSQLの記述に活かしたい人はSQL実践入門(ミック)を読むのがおすすめ。
https://www.amazon.co.jp/dp/B07JHRL1D3/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
論文2について
Abstract
本論文では、ARIES ( Algorithm for Recouery and Isolation Exploiting Semantics ) と呼ばれるシンプルで効率的な手法を紹介します。
この手法では、trxの部分的なロールバック、細分化された(例えばレコード)ロック、WAL (Write-ahead logging) を用いたリカバリをサポートします。
ARIESでは、システム障害後の再起動時に、敗者となったtrxのロールバックを実行する前に、「失われたすべての更新をやり直すために履歴を繰り返す」というパラダイムを導入しています。
また、ARIESは、各ページのログシーケンス番号を使用してページの状態とそのページのログに記録された更新を関連付けています。
trxのすべての更新は、ロールバック中に実行されたものも含めてログに記録されます。
ロールバック中に書き込まれたログレコードと前進中に書き込まれたログレコードを適切に連鎖させることにより、再起動中の繰り返しの失敗やネストされたロールバックに直面しても、ロールバック中に制限された量のロギングが保証されます。
ARIESはファジーチェックポイント、選択的な再起動と遅延再起動、ファジーイメージコピー、メディアリカバリー、高コンカレンシーロックモード(e.g. increment / decrement) をサポートしています。これらのロックモードは操作のセマンティクスを利用しており、操作のロギングを行う機能が必要です。
ARIESは、実装可能なバッファ管理ポリシーに柔軟に対応しています。様々な長さのオブジェクトを効率的にサポートします。
更に、再起動時の並列処理、ページ指向のREDO、論理的なUndoを可能にすることで、同時実行性とパフォーマンスを向上させます。
...
出典: ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging (筆者訳)
感想とメモ
Ariesの論文はかなり難しい...。
web上のリソースを色々見てようやく上辺の理解ができた気がする。
そんなわけで、Ariesの仕組み自体は私が参考にしたリソースを記録するに止める。
TODO: 続き
論文3について
感想とメモ
ロックとトランザクション(以下、txn)の分離レベルを解説している論文。
ここら辺の話はDBの入門書でも見た気がするけど、ロックの階層の話や、ANSI SQL標準以外の分離レベルは初めて知った。
この論文もなかなか歯ごたえがあり、証明部分などは追いきれていないので時間があるときに復習したい。
ロックに関するお話
まずは、そもそも「ロックとはなんだったけ」となったので、復習する。
つまるところ、txnの一貫性を保つために同じオブジェクトに同時にアクセスできるユーザーを制限するための機構だ。
ロック
ロックとは、ユーザーがデータベースのテーブルやレコードにアクセスするのを制限する処理です。複数のユーザーが同じテーブルやレコードに同時にアクセスする可能性がある場合に、ロックをかけます。テーブルやレコードをロックすると、一度に 1 人のユーザーだけがデータに影響する処理を行えるようになります。
ロック制御は、複数のユーザーが、データベースの同じレコードに同時にアクセスしたり変更する場合に特に重要です。複数のユーザーが同時に使えるデータベースは便利ですが、問題が発生することもあります。たとえば、ロックしていない場合、2 人のユーザーが同時に同じレコードを変更しようとすると、正確なデータが取得できなかったり、一方のユーザーが必要とするデータをもう一方のユーザーが削除してしまう可能性があります。しかし、いったん 1 人のユーザーがアクセスしたレコードを、他のユーザーが一時的に変更できないようにロックできるようにしておくと、このような問題は発生しません。ロックすることによって、データベースへの同時アクセスによる問題の発生を最小限に抑えることができます。
出典: ACTIAN ロック レベルと分離レベル
さて、ロックについては大きく考えることが2つある。
観点1. どの粒度でロックをかけるか(DB全体?レコード毎?)
観点2. どのようなロックをかけるか?(他の人は読み込みすらできない?読み込みは許す?)
まずは観点1「ロックの粒度」について検討する。
観点1「ロックの粒度」
ロックを掛ける単位(lockable unit)の例が論文に記載されているので、まずはそれを確認する。
locakble unitの例
db, table, area, file, 個々のrecords, 複数のfield値, field値
左から右にいくほど小さな単位になっている。
ここで、「areaって何?」となったのだが、以下のサイトによると表とindexなどをまとめたものっぽい?
他の要素に関してはwikiのデータ階層に記載がある。
http://itdoc.hitachi.co.jp/manuals/3020/3020645050e/FIGURE/ZU060120.GIF
http://itdoc.hitachi.co.jp/manuals/3020/3020645050e/W4500164.HTM
{kind=link}
一部要素を階層で表現すると以下のようになる。
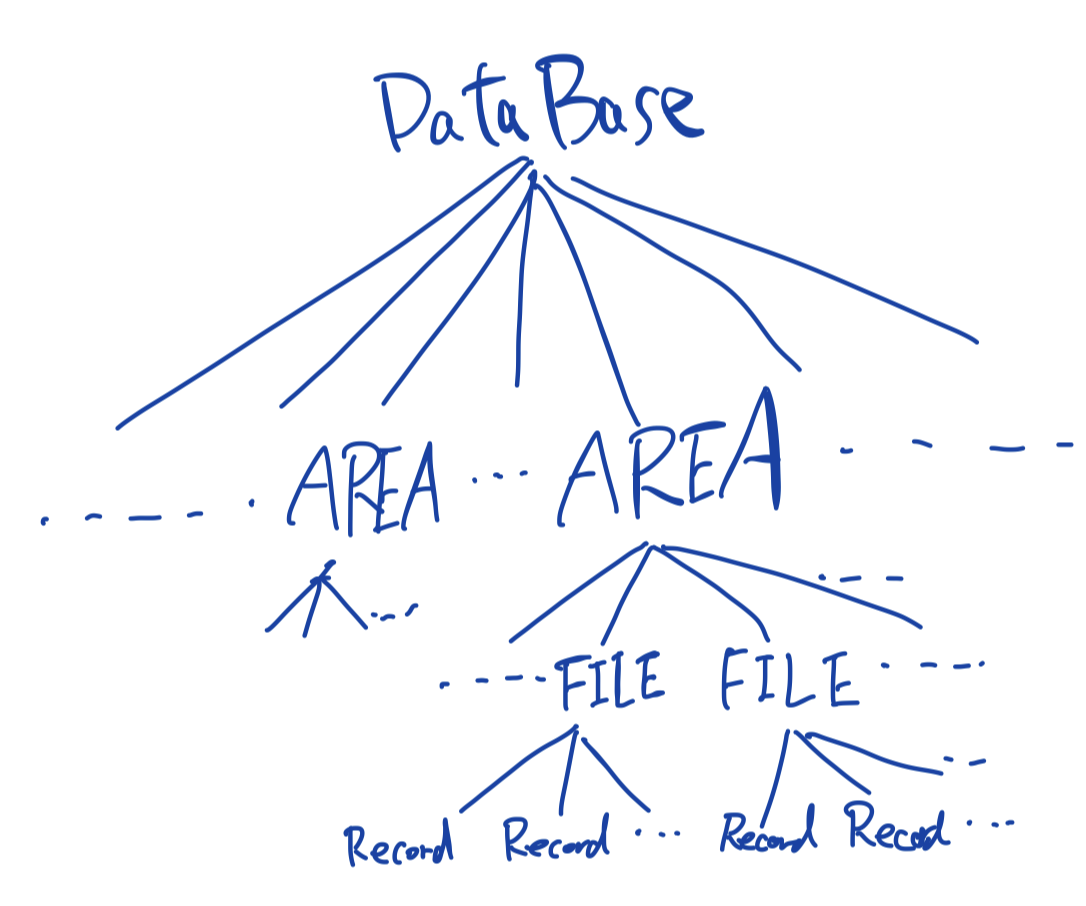
表単位の様な「粗いロック」とレコード単位のような「細かいロック」の選択にはconcurrencyとoverheadに関するトレードオフがある。
細かいロックは並列性が高く、(数レコードしかアクセスしないような)単純なtxnに適している。
反対に、多くのレコードにアクセスするような複雑なtxnに対しては細かいロックはオーバーヘッドが大きくなり、そういった場合は粗いロックが好ましい。
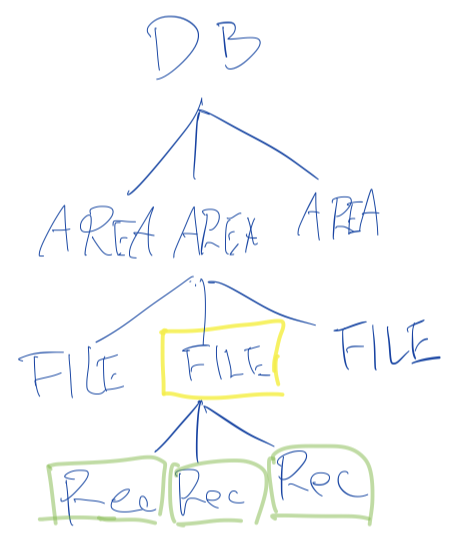
例えば、以下の図のようにFILEに対するロック(黄色)を掛けると、その下にあるRecordsのロック(緑)を纏めて得られる。
【 fig 1 】
次に、観点2「ロックの種類(モード)」について考える。
観点2「ロックの種類(モード)」
ロックの種類を複数考えることで、一貫性を保ちつつ並列性を高めることができる。
直感的に考えても、「2人が同時に同じレコードを読み込む」ことはOkだが、「誰かが書き込み中のレコードに他の人が読み込みを行う」のはNGだとわかるだろう。
まずはシンプルな2つのロックを考える。
- X (eXclusive) ... 資源を占有する。この間、他者は書き込みも読み込みもできない。レコードの書き込み時などに利用する。
- S (Share)... 資源を共有する。この間、他者は書き込みができない。レコードの読み込み時などに利用する。
例えばAさんがある資源(ノード)のXロックを取得している場合、Bさんはその資源にXロックもSロックも取得できない。
Aさんが取得しているロックがSである場合は、BさんはSロックが取得できる。
なお、fig1のようにFILEに専有ロックが掛かった場合、その下のRecordsにも専有ロックが掛かることに注意。
ロックはこの2種類だけで十分だろうか?
fig1のようにFILEに専有ロックがかかっている場合、そのひとつ上のAREAに専有ロックは取得できないはず(これができてしまうと、その下のFILEに専有ロックが掛かる)だが、今はそれをうまく表現できていない。
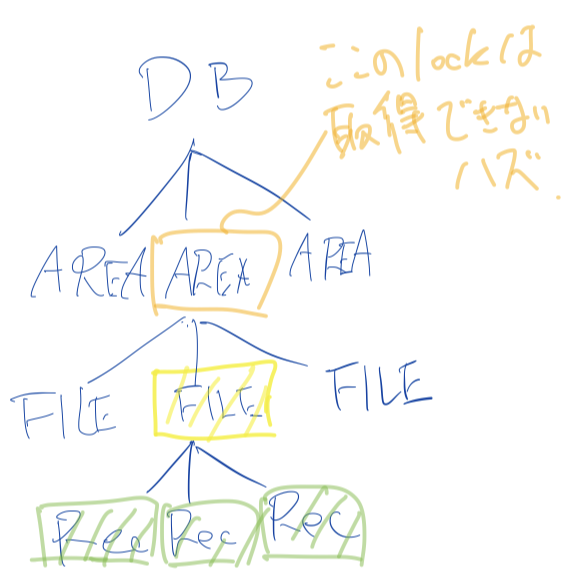
よって、これを解決するため、更にI(intention mode)を考える。
intention modeは「ロックが下位ノード(より細かい粒度)で行われている」ことを示すタグのような役割を果たす。
あるノードのS,Xロックを取得する前にその上位ノードのIロックを取得するようにすることで、全体の整合性を保つ。
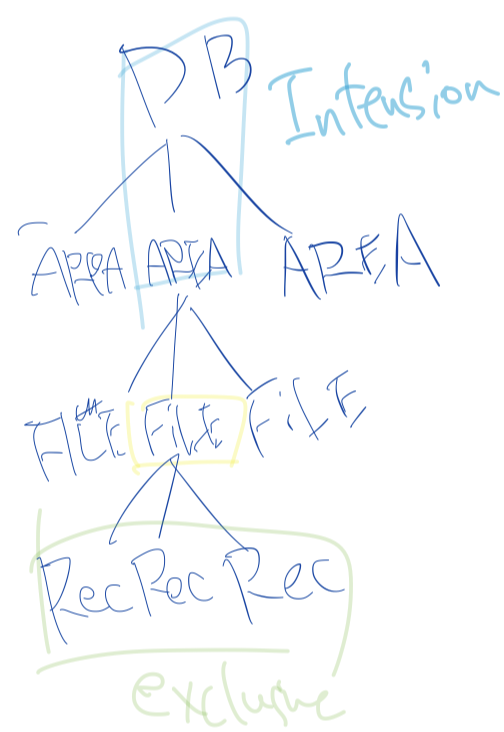
intention modeは以下の3種類を考える。
- IS (Intention Share) ... 資源を意図共有する。 下位ノードの
S, ISロックを得られる。 - IX (Intension eXclusive) ... 資源を意図専有する。下位ノードの
X, S, SIX, IX, ISロックを得られる。 - SIX (Share and Intension eXclusive) ... 資源を共有・意図専有する。全ての下位ノードの
Sロックを暗黙的に取得し、明示的に下位ノードのX, SIX, IXロックを得られる。
ISは下位ノードのSロックを取得するために、IXは下位ノードのXロックを得るために用いる。
SIXはかなり曲者だが、「あるFILEのフルスキャンと一部レコードの更新」を考えてみよう。
SIXが無い場合は
(a)FILEのXを取得
(b)FILEのIXとその下位のRecord一つ一つのSorXを取得
のどちらかになるが、(a)は並列性が低く、(b)はロックのオーバーヘッドが高い。
このような用例は多いので、SIXが存在する。
これまで考えてきたロックの両立関係は以下のようになっている。
(NLはNo Lockを表す)

出典: Granularity of Locks and Degrees of Consistency in a Shared Data Base. (1975)
SIXがSの両立とIXの両立の積集合になっている。
また、論文にはロックの半順序関係が記載されている。
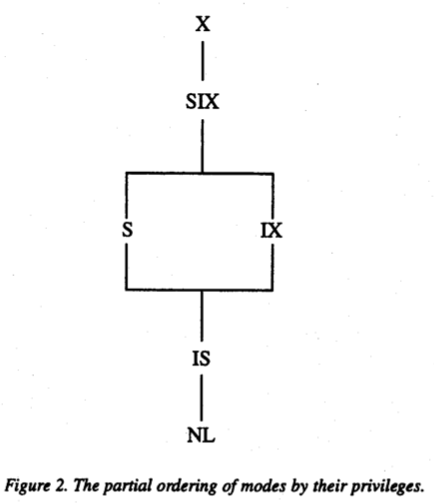
出典: Granularity of Locks and Degrees of Consistency in a Shared Data Base. (1975)
ロックのプロトコル
ロックはroot(最上位)からleaf(最下位)へ要求し、leafからrootへ開放するように使用する。
具体的には以下のルールに従う。
- あるノードの
S,ISロックを要求する前に、その上位全てのノードのIXorISロックを取得する必要がある - あるノードの
X,SIX,IXロックを取得する前に、その上位全てのノードのSIXorIXロックを取得する必要がある - ロックは
leafからrootへ開放していく
ロックの例
最後にロックの例を見ていく。
(a) recordRを読み込みたい
1. Rを含むdatabaseのISロックを取得
2. Rを含むareaのISロックを取得
3. Rを含むfileFのISロックを取得
4. RのSロックを取得
(b) fileFの読み込みと書き込みを行いたい
1. Fを含むdatabaseのIXロックを取得
2. Fを含むareaのIXロックを取得
3. fileFのXロックを取得
(c) fileFのフルスキャンとレコードに対して幾つかの更新を行いたい
1. Fを含むdatabaseのIXロックを取得
2. Fを含むareaのIXロックを取得
3. fileFのSIXロックを取得
(a)と(b)は両立できないが、(a)と(c)は両立できることに注意しよう。
この論文には他にも
- データ階層をDAGに一般化した場合のロック
- その他、ロックの正当性の説明
を含む様々な話題が記載されている。
その他参考にした記事
- https://qiita.com/s0t00524/items/56c9d95637d1d356a291
- https://qiita.com/zesu/items/089e1c88259d2b81e41c
txnの分離レベルに関するお話
分離レベルのお話をする前に、まずはtxnについて復習する。
DBはデータに関する言明(assertion)を持つが、それを全て満たしている場合に一貫しているといえる。
しかし、DBを現在の状態から新しい(整合性のある)状態に変更するために、一時的に不整合になる必要がある場合がある。(例えば銀行の送金等)
txnとは、この様な一連の処理を纏めた「一貫性を保つ処理の単位」といえる。
txnについて復習したところで、分離レベルの定義を確認しよう。
トランザクション分離レベル (トランザクションぶんりレベル)または 分離レベル (英: Isolation) とは、データベース管理システム上での一括処理(トランザクション)が複数同時に行われた場合に、どれほどの一貫性、正確性で実行するかを4段階で定義したものである。隔離レベル 、 独立性レベルとも呼ばれる。トランザクションを定義づけるACID特性のうち,I(Isolation; 分離性, 独立性)に関する概念である。
分離レベルの話はDBの入門書でも書かれていることが多いと思うので、知っている人も多いと思う。
恐らく以下のような定義だろう。(私が知っていたのも以下の定義だ。)
ANSI/ISO SQL標準で定められている分離レベルは、下記の4種類で定義されている。
SERIALIZABLE(直列化可能)
複数の並行に動作するトランザクションそれぞれの結果が、いかなる場合でも、それらのトランザクションを時間的重なりなく逐次実行した場合と同じ結果となる。このような性質を直列化可能性(Serializability)と呼ぶ.SERIALIZABLEは最も強い分離レベルであり、最も安全にデータを操作できるが、相対的に性能は低い。ただし同じ結果とされる逐次実行の順はトランザクション処理のレベルでは保証されない。REPEATABLE READ(読み取り対象のデータを常に読み取る)
ひとつのトランザクションが実行中の間、読み取り対象のデータが途中で他のトランザクションによって変更される心配はない。同じトランザクション中では同じデータは何度読み取りしても毎回同じ値を読むことができる。
ただし ファントム・リード(Phantom Read) と呼ばれる現象が発生する可能性がある。ファントム・リードでは、並行して動作する他のトランザクションが追加したり削除したデータが途中で見えてしまうため、処理の結果が変わってしまう。READ COMMITTED(確定した最新データを常に読み取る)
他のトランザクションによる更新については、常にコミット済みのデータのみを読み取る。 MVCC はREAD COMMITTEDを実現する実装の一つである。
ファントム・リード に加え、非再現リード(Non-Repeatable Read)と呼ばれる、同じトランザクション中でも同じデータを読み込むたびに値が変わってしまう現象が発生する可能性がある。READ UNCOMMITTED(確定していないデータまで読み取る)
他の処理によって行われている、書きかけのデータまで読み取る。
PHANTOM 、 NON-REPEATABLE READ 、さらに ダーティ・リード(Dirty Read) と呼ばれる現象(不完全なデータや、計算途中のデータを読み取ってしまう動作)が発生する。トランザクションの並行動作によってデータを破壊する可能性は高いが、その分性能は高い。
この論文では分離レベルを次数(degree)0~3までを定義しており、ANSI SQL標準の分離レベルとの対応は以下のようになっている。
- 次数1 - READ UNCOMMITTED
- 次数2 - READ COMMITTED
- 次数3 - REPEATABLE READ
- 次数0, SERIALIZABLEは対応なし
各次数の分離レベルのサマリが以下のように記載されている。
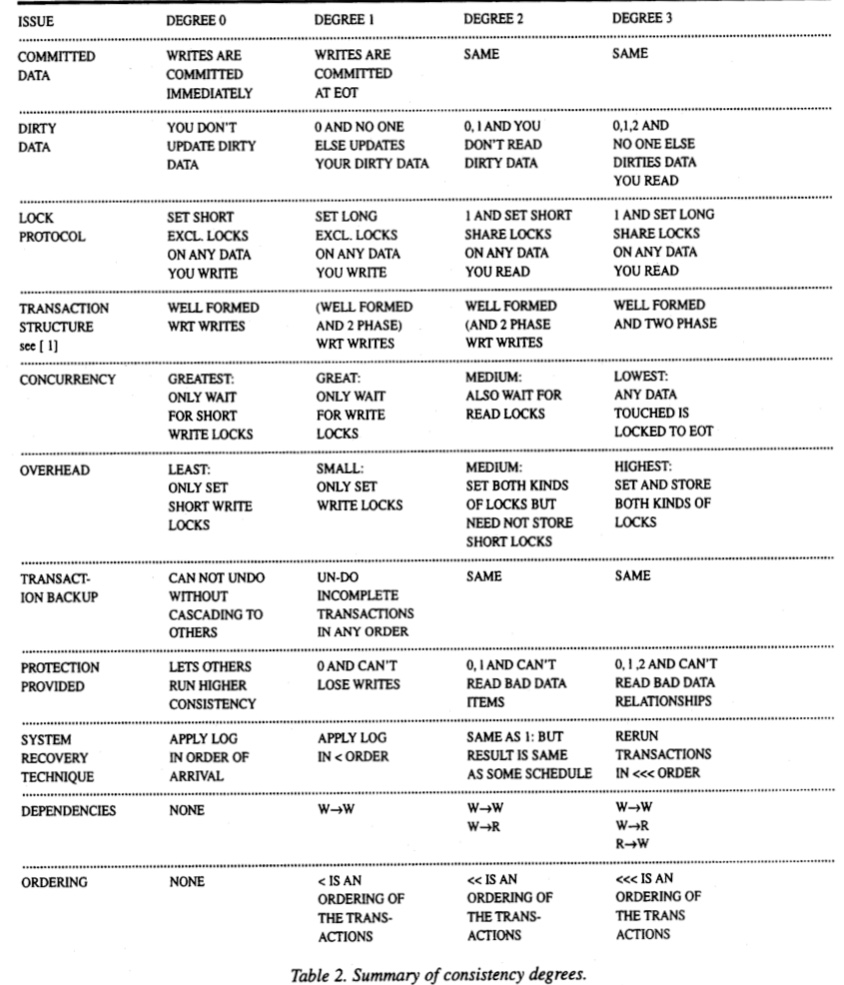
TODO: 語彙に関する補足を記載
その他参考にした記事
- https://blog.acolyer.org/2016/01/06/degree-of-consistency/
- https://qiita.com/song_ss/items/38e514b05e9dabae3bdb
論文4について
論文5について
Abstruct
本稿では、R*分散型データベースシステムのトランザクション管理の側面を扱っています。
主に、R*のコミットプロトコルであるPresumed Abort(PA)とPresumed Commit(PC)の説明に重点を置いています。
PAとPCは、よく知られている2P(two-phase)コミットプロトコルの拡張版です。
PAは読み取り専用のトランザクションとマルチサイトの更新トランザクションに最適化されており、PCはその他のマルチサイトの更新トランザクションに最適化されています。
この最適化により、サイト間のメッセージ・トラフィックとログの書き込みが減少し、その結果、応答時間が改善されました。
また、この論文では、R*の分散デッドロックの検出と解決に関するアプローチについても触れています。
出典: Transaction Management in the R* Distributed Database Management System. (1986) (筆者訳)
感想とメモ
この論文では主に、分散環境でトランザクションを処理する方法として2PC(2相コミット)に基づくプロトコルを説明している。
2PL(二相ロック)と名前が似ているけど、全然別物であることに注意。
というわけで、これから3つのコミットプロトコルについて見ていく。
- 2PC (two phase commit) ... 2相コミット
- PA (presumed abort) ... 推定アボート
- PC (presumed commit ... 推定コミット
前提知識の復習
ただ、いきなりこれらの話題に入る前に予備知識として「分散DB」と「分散トランザクション」について復習する。
分散DBの定義をwikipediaから引用する。
分散データベース(ぶんさんデータベース、英: distributed database)は、1つのデータベース管理システム (DBMS) が複数のCPUに接続されている記憶装置群を制御する形態のデータベースである。物理的には同じ場所の複数台のコンピュータで構成される場合や、コンピュータネットワークで相互接続されたコンピュータ群に分散されている場合などがある。
出典: wikipedia
要は「複数のDBを、まるで1つのDBであるかのように使えるようにしたシステム」ぐらいのイメージでいいんじゃないだろうか。
以前にGammaについて勉強したが、これも分散DBの一種だ。
wikipediaよりゆるーい説明としては、ここのサイトがわかりやすかった。
https://itmanabi.com/2phase-commit/
分散トランザクション(ぶんさんトランザクション、英: Distributed transaction)は、コンピュータ分野におけるトランザクション処理の処理形態の1つであり、ネットワーク上の2つ以上のホスト(処理するコンピュータ)が関連する、1まとまりの操作(処理、取引、トランザクション)のことを示す。
出典: wikipedia
「複数のマシンが関わるトランザクション」ぐらいの理解で良さそう。
もう少し知りたい人はここを見よう。
https://wa3.i-3-i.info/word16108.html
そんなわけで、分散トランザクション(以下、分散txn)は複数のDBに対する処理(txn)が一纏めになっているため、分散trxのコミットプロトコルも「各DBに対するtxn全てが作動する(commit)か、そのどれも作動しない(abort)」のどちらかでないといけない。
また、一般にコミットプロトコルの望ましい特性として以下が挙げられている
- 常にtxnの原子性が保証される
- 短時間の後にコミット処理の結果を「忘れる」機能
- ログ書き込みとメッセージトラフィックに関するオーバーヘッドが最小限
- 障害のない場合に最適化されたパフォーマンス
- 完全または部分的な読み取り専用txnの効果的な利用
- 一方的な
abortを実行する能力の最大化
1は当然として、2の「忘れる」というのは多分txnを「終わらせる」とざっくり言い換えてもいいんだろうか。
3もそれはそう。
4は「障害がない場合のほうが多いよね」という前提のもとでは言えそう。
5は、読み取りtxnは更新がない分最適化できそうだよねという感じは確かにする。
6はabortを強制できる方が何かあった時安全だよねという理解で良い?
この論文ではこの特性の内、パフォーマンスに関わる部分が重点的に説明されている。
2PC 二相コミット
仕組み
2PCではある1つのノードがコーディネーター(幹事)として指定され、他のすべてのノードは従属ノード(部下)として扱われる。
その上で、txnのコミットを行う際に2PCは以下の2段階で実施される。
- 準備フェーズ
- コーディネーターは全ての部下に
PREPAREリクエストを送信する。 - 部下は夫々コミットの準備ができていれば
yesを、コミットができなければnoを返す。
- コーディネーターは全ての部下に
- コミットフェーズ
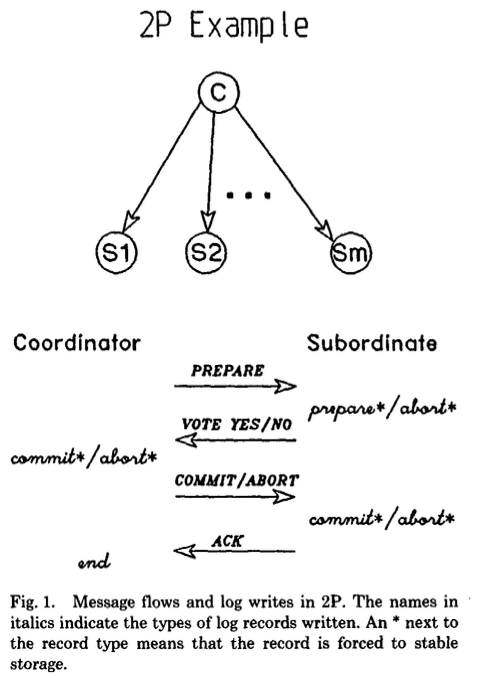
出典: Transaction Management in the R* Distributed Database Management System.
参考: 2PCの更に詳しい説明はデータ指向アプリケーション 9.4.1を見ると良さそう
障害が発生したら
障害が発生した部分がネットワークか部下ノードであれば、以下のような対応になる。
- 準備フェーズ : PREPAREリクエストを送る段階で障害が発生した場合は、障害が発生したトランザクションIDに対するABORTのリクエストを全ての部下に送る。復旧後、障害に関わった部下はコーディネーターに状況を聞く。
- コミットフェーズ : この段階で障害が発生した場合、コーディネーターは成功するまでリトライし続ける。
コーディネーターに障害が発生した場合は、以下のような対応になる。
- PREPAREリクエストを送る前 : 部下のトランザクションは夫々安全に中断される。
- PREPAREリクエストを送った後 : 部下がyes/noを返した場合、それ以降部下は一方的な中断ができず、コーディネータからのリクエストを待つ必要がある。そのため、この時点でコーディネータ(や、ネットワーク)に障害が発生した場合、部下のトランザクションは未確定のまま待ち続けることになる。
- コーディネータの復旧時、トランザクションログを読むことで未確定のトランザクションの状態を確定させる必要がある。
- コミット記録がログに存在しない場合、そのトランザクションは中断される
階層2PC
これまで考えてきた2PCはトランザクションの実行モデルがmultilevel(>2) trees of processが発生する場合は不十分だ、ということで紹介されたのが 階層2PC。
階層2PCではノードはツリーに配置され、各役割は以下のようになっている。
- ルート : コーディネーター
- リーフ : 部下ノード
- 中間ノード : 両方として機能
中間ノードは以下のような動きをする。
- 親からPREPAREリクエストを受信すると、それを下向き(子)に伝播する。
- 子から投票を受け取ると、全ての子がyesを投じた場合はyesを、いずれかの子がnoを投じた場合はnoを上向きに投票/伝搬し、投票がない場合はABORTを送信する。
- 親からABORT/COMMITを受け取った場合、強制書き込みを行った後、親にACkを送信し子にABORT/COMMITを送信する。
PA 推定アボート
PAは、基本は2PCと同じだが、コーディネーターがtxnについて情報がない場合、ABORTだと推定する特徴を持つ。
この変更は以下のようなパフォーマンス上の利点がある。
- コーディネーターが
ABORTを送信した後、部下からのACKを待たずにtrxを忘れられる。また、部下の名前をABORTレコードに記録する必要もない。- 加えて、部下は
ABORTレコードを強制的に書き込む必要がない
- 加えて、部下は
- (部分的な)読み取りtxnの効率化が可能
PREPAREを受信し、かつ更新がない場合、READ VOTEを送信し即座にロックを開放しtxnを忘れられる (ログは書き込まれない)- コーディネーターは
READ VOTEを送ってきた部下をコミットフェーズから除外できる
以下の状態遷移図はより一般的なものだが、ABORT状態が無いことがわかる。
(IDLEは各プロセスの初期状態と最終状態を示す)
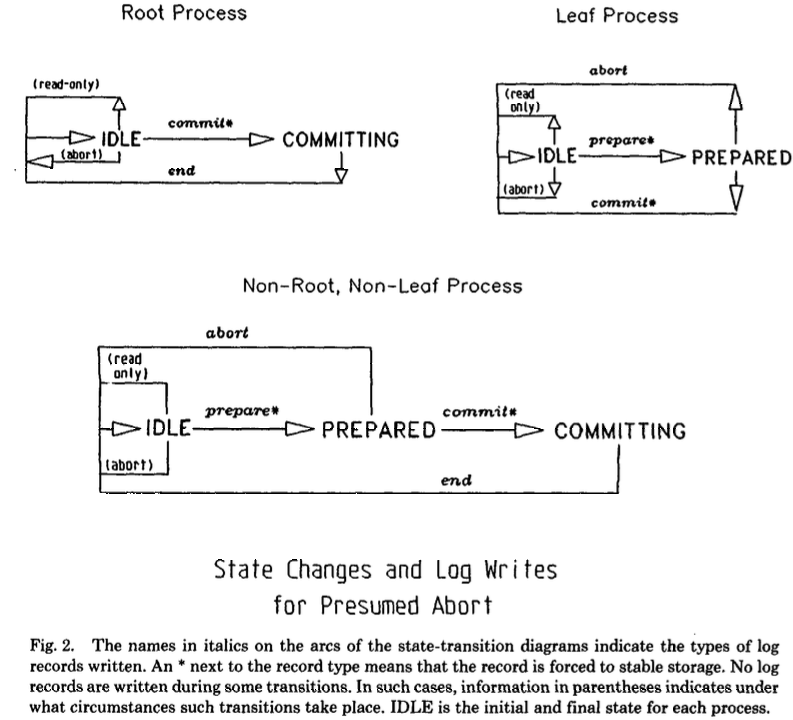
出典: Transaction Management in the R* Distributed Database Management System.
障害が発生した場合の対応は論文か参考サイトを見てほしい。
TODO: 2PCだと読み取りtxnの最適化ができないのか
PC
PCは、基本は2PCと同じだが、コーディネーターがtxnについて情報がない場合、COMMITだと推定する特徴を持つ。
この方式は、「殆どのコミットは成功する」という前提に立っている。
この変更は以下のようなパフォーマンス上の利点がある。
- コーディネーターが
COMMITを送信した後、部下からのACKを待たずにtxnを忘れられる。- 加えて、部下は
COMMITレコードを強制的に書き込む必要がない
- 加えて、部下は
- (部分的な)読み取りtxnに対してPAと同様の最適化が可能
しかし、以下のような欠点がある。
- コーディネータは部下が準備状態になる前に、部下の名前を安全に記録する必要がある。
- そうしなければ、準備フェーズの間にコーディネータに障害が起きた場合に不整合が起きてしまう。
このため、PCではコーディネータがPREPAREを送信する前にcollecting record(収集レコード)を強制的に書き込む必要がある。
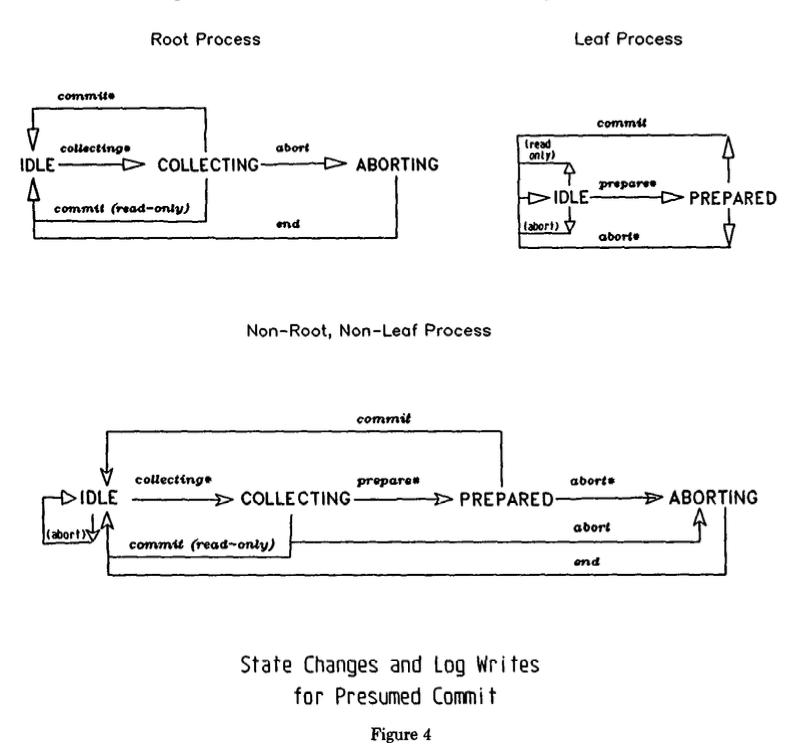
出典: Transaction Management in the R* Distributed Database Management System.
障害が発生した場合の対応は論文か参考サイトを見てほしい。
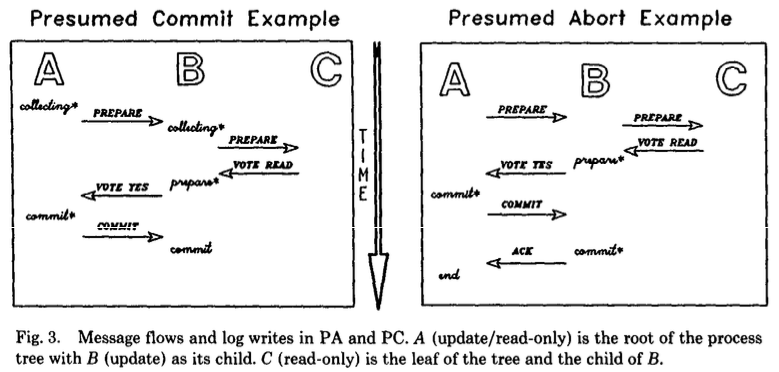
出典: Transaction Management in the R* Distributed Database Management System.
パフォーマンスの比較
この論文によれば以下の通り。
うーん、なんだか分かったような分かっていないような...微妙な理解度だ。
自分でトランザクションの動きをちゃんと図で書いてみないと理解出来なさそう。
参考
- https://mwhittaker.github.io/prelim_notes/html/transaction-management-in-the-r-distributed-database-management-system.html
- https://blog.acolyer.org/2016/01/11/transaction-management-in-r/
- https://sookocheff.com/post/databases/distributed-transaction-management/
- https://people.eecs.berkeley.edu/~fox/summaries/database/rstar_trans.html
- https://people.eecs.berkeley.edu/~fox/summaries/database/rstar_trans.html